Title: Comparison of normalized gain and Cohen’s d for analyzing gains on concept inventories
Authors: Jayson M. Nissen, Robert M. Talbot, Amreen Nasim Thompson, Ben Van Dusen
First author’s institution: California State University, Chico
Journal: Physical Review Physics Education Research 14 010115 (2018)
Measuring student learning is a complicated but an important part of physics education research. Typically, this has been accomplished by comparing pre- (start of semester) and post-test (end of semester) scores on conceptual inventories. To compare the results from different instructors and different semesters, the scores are typically standardized using the normalized gain, which we introduced in the previous PERbites post. Essentially, the normalized gain is the fraction of “knowledge” gained on average to the highest possible amount of “knowledge” that could have been gained. The formula is shown in figure 1. Previous work has found that inferences based on the normalized gain may lead to incorrect conclusions about gender inequality in STEM courses, meaning that another “gain” statistic may not reach the same conclusion. In today’s paper, the authors examined whether using normalized gain or Cohen’s d, a gain statistic commonly used in the social sciences and education research, could lead to different inferences about student learning as measured by conceptual inventories in physics classes.

The researchers started by selecting nine conceptual inventories to analyze using the normalized gain and Cohen’s d. The conceptual inventories data were obtained from the LASSO data set, which is a large data set originally collected to analyze the impact of learning assistants on student learning in many STEM disciplines. The conceptual inventories that are included in the LASSO data set were all administered through the online LASSO platform.
The researchers then removed students and classes that did not provide reliable data such as students who completed the test too quickly to have actually read all the questions, students who skipped more than 20% of the questions, students whose gain was two standard deviations below the class gain since this means the student would have to substantially unlearn the material while taking the course, and classes where less than 60% of the students completed the test. To account for the non-complete data set, the researchers then a technique called multiple imputations to simulate the missing values based on the rest of the data. This technique involves predicting the missing values in the data set, running the analysis, and then repeating a number of times before combining the results together using averages and other methods designed to combine the results of multiple experiments.
Since there are actually multiple ways to compute the normalized gain, the researchers computed it in all three ways and then looked at the correlation between them. All three ways of computing the normalized gain were highly correlated (r>0.9 where r=1 is perfect correlation and r=0 is no correlation) so the researchers decided to use Hake’s method of calculating the normalized gain (figure 1) to conduct their analysis first.
So what did they find? First, the researchers found that the normalized gain and Cohen’s d were positively correlated (r=0.75) but that they only share 56% of their variance (which is essentially how much the change in the normalized gain or Cohen’s d affects the change in the other). Since these two statistics are supposed to measure the same thing, not sharing 44% of their variances is a concern. To try to account for this, the researchers then looked at how the pre-test mean, the pre-test standard deviation, the post-test mean, the post-test standard deviation, and the gain (post-test mean minus pre-test mean) were correlated to the normalized gain and Cohen’s d. They found that the pre-test mean and the pre-test standard deviation were correlated with the normalized gain but not Cohen’s d while all the others were either correlated with both the normalized gain and Cohen’s d or neither.
To determine how much of the difference between the normalized gain and Cohen’s d could be explained the pre-test mean and the pre-test standard deviation, the researchers ran multiple linear regression models. Multiple linear regression models try to fit a line to the data and can also be used to account for how much of one variable can explain another. The multiple part means that variables are added one at a time and the change in explained variance can then be attributed to the added variable. Doing so, the researchers found that Cohen’s d explained 55% of the variance in the normalized gain (the same amount as using correlations) and an additional 37% could be explained by the pre-test means and pre-test standard deviations. The researchers concluded that this means the normalized gain is positively correlated with the pre-test statistics and that the normalized gain is then likely biased towards populations with higher pre-test scores while Cohen’s d does not exhibit such biases.
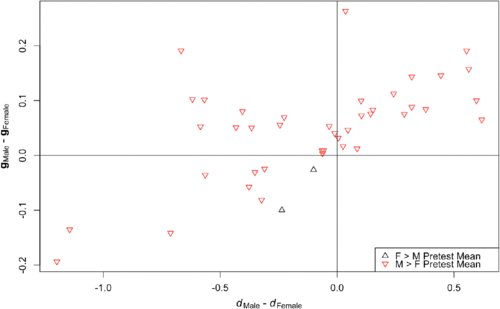
To test this hypothesis, the researchers then compared the gender differences between males and females on the conceptual inventories using both the normalized gain and Cohen’s d. Since males typically outperform females on conceptual inventories (and did so in 41 of the 43 courses in the dataset), if the normalized gain is actually biased towards the higher pre-test population, there should be more cases in which males outperform females as measured by the normalized gain than as measured by Cohen’s d. Of the 43 courses studied, 33 showed a larger effect on males when the normalized gain was used while only 22 of the 43 courses showed a larger effect when Cohen’s d was used. A plot comparing the normalized gain and Cohen’s d is shown in figure 2. Thus, it appears that the normalized gain is actually biased in favor of populations with higher pre-test scores.

So what can we take away from this paper? First, the normalized gain overestimates student inequities and should not be used in research studies. Instead, researchers should use Cohen’s d. This is especially important when studying students who may come from disadvantaged backgrounds since they are likely to have lower pre-test scores than students who come into the class with better preparation and hence will appear to have learned less than their more advantaged peers as measured by the normalized gain. Second, as instructors at teaching intensive institutions are often required to provide evidence of student learning for tenure and promotion, using the normalized gain may result in scores that appear to show less learning than actually occurred. While whether ’tis nobler in the mind to use Cohen’s d is an open question, this paper shows that the normalized gain is a statistic biased towards students with higher pre-test scores and its use should be replaced by Cohen’s d.
Figures used under Creative Commons Attribution 4.0 License.
I am a postdoc in education data science at the University of Michigan and the founder of PERbites. I’m interested in applying data science techniques to analyze educational datasets and improve higher education for all students